Structured Data for the AI-Search Era: The Practical Setup
Schema doesn't rank you in an LLM — that part is snake oil. What it actually does is disambiguate your entities and hand the retriever clean structure to parse. This is the practical setup: which schema types earn their keep, why a connected @graph beats scattered JSON-LD islands, and the exact wiring this site runs.
The citation playbook called structured data move number six and warned you off the snake oil in the same breath. The entity post said sameAs is part of how a model resolves who you are. This is the post that actually wires it up — the practical setup, written from the seat of someone who hand-builds the schema on this site rather than someone selling a plugin that promises to “optimize you for AI.”
Start with the disappointing truth, because it saves you from the expensive mistakes. Structured data does not rank you in an LLM. There is no schema type, no special property, no markup incantation that makes ChatGPT cite you more. Anyone who tells you otherwise is selling the part of GEO that didn’t survive contact with Google’s own documentation. What schema does — and this is worth doing well — is two unglamorous things: it disambiguates your entities so the engine knows exactly who and what it’s looking at, and it hands a clean, machine-parseable structure to a retriever that would otherwise have to infer everything from your HTML. Neither is magic. Both move you up the trust ladder.
What schema does for an answer engine (and what it doesn’t)
A retriever pulls a passage out of your page and has to answer two questions about it: what is this text about, and whose claim is this? Clean HTML answers the first reasonably well on its own. Structured data answers the second far better than prose ever can. When your markup says, in a vocabulary every engine already parses, “this article was written by this Person, who is the same entity as these profiles, published on this site, on this date,” you’ve removed the ambiguity that — as the entity post laid out — is the single most common reason a source gets retrieved but never named.
What it does not do is inflate your relevance. Schema is a clarity layer, not a ranking lever. Google has said plainly that its AI surfaces use the same core systems as regular search and that there’s no AI-specific markup to add. Bing and ChatGPT lean harder on clean rendered HTML than on your JSON-LD. So the honest framing is: structured data is table stakes for being understood, and it’s worthless as a trick for being promoted. Do it because it removes friction, not because you think it’s a cheat code.
The connected @graph: the one idea that matters
Here’s the part most schema tutorials skip, and it’s the part that actually counts in the AI era. Most sites bolt on schema as disconnected islands — an Article block here, an Organization block there, a BreadcrumbList somewhere else — each a standalone JSON-LD script that never references the others. A parser reading those islands sees three unrelated objects and has to guess that the article’s author is the same person as the organization’s founder, that the breadcrumb belongs to this page, and so on.
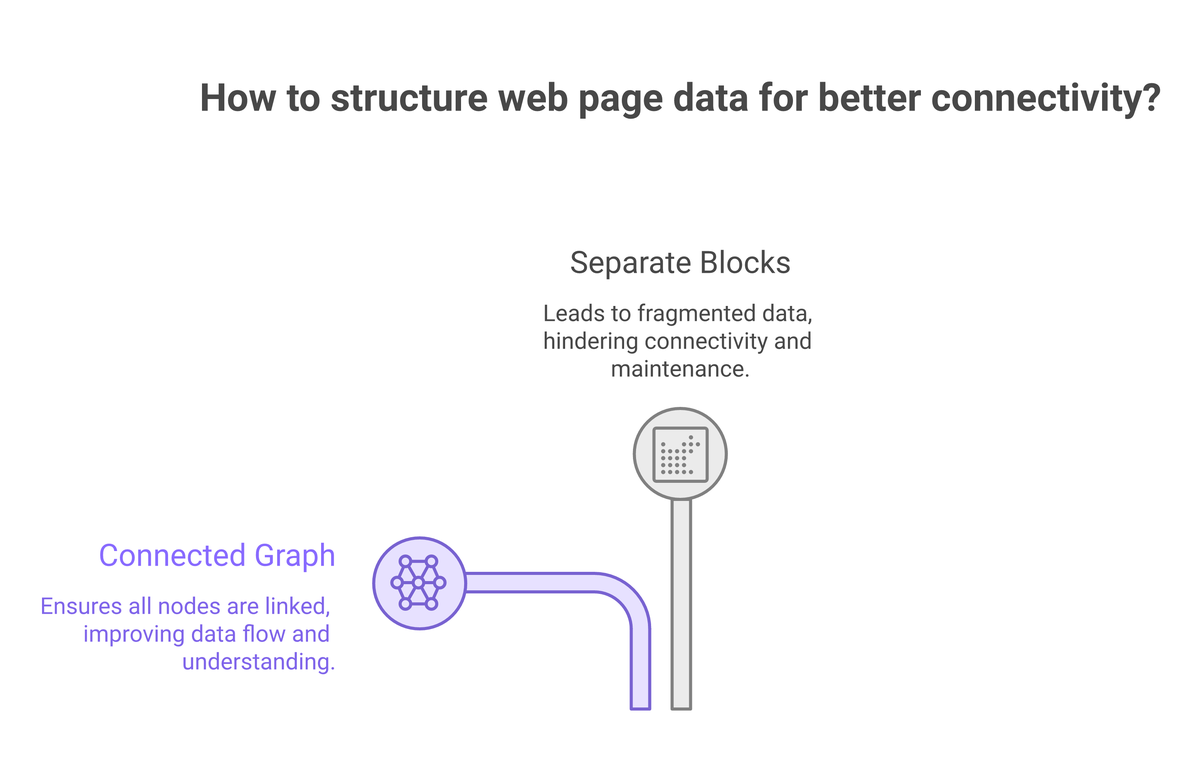
A connected @graph removes the guessing. You publish one graph in which every entity has a stable @id, and entities reference each other by that id instead of repeating themselves. The Article points to its author by the Person’s @id; the Person is defined once, anchored at your About page; the WebPage declares it isPartOf the WebSite; the breadcrumb hangs off the page. The result is a single, navigable web of nodes — exactly the entity-relationship model an LLM-driven retriever already thinks in. You’re not handing the engine a pile of facts; you’re handing it a resolved entity it can trust at a glance.
If you take one thing from this post: connect your schema by @id, don’t scatter it. That single structural choice does more for entity resolution than any individual property you could add.
The types that actually earn their keep
You do not need forty schema types. You need a small set, wired together. Here’s the working list and why each one is on it.
Person(orOrganization) — the anchor. This is the entity everything else hangs off. Define it once, at a stable@id(this site anchors the Person at/about/), with a real description, ajobTitle/role, and — critically —sameAs. Skip this and your articles have an author string but no resolvable identity behind it.WebSite— the publication. Names the site as a thing, declares its publisher (your Person/Organization), and is where aSearchActionlives if you have site search. It’s the parent the rest of the graph reports up to.Article/BlogPosting— the content unit. Carriesheadline,datePublished,dateModified, and references the author and publisher by@idrather than restating them. This is where freshness signals live — and a reminder from the reframe work on this site: bumpdateModified, never fakedatePublished.BreadcrumbList— the place. Tells the engine where this page sits in your site’s hierarchy. Cheap to generate, genuinely useful for situating a passage.FAQPage— only when the Q&A is real. A page with genuine question-and-answer pairs gives a retriever pre-chunked, liftable units — and AI answers love lifting Q&A verbatim. The catch: use it only where real questions are really answered. Stuffing fake FAQs to chase rich results is exactly the manipulation Google clamped down on, and it reads as spam to an LLM too.
Notice what’s not on the list: speculative “AI-only” vocab, llms.txt as a ranking file, bought review schema, or any property a vendor invented to sound future-proof. The boring five, connected properly, beat the exotic forty every time.
sameAs is the entity-resolution backbone
If the connected @graph is the skeleton, sameAs is the spine. It’s the property that says these accounts, profiles, and pages are all the same entity as me — your X, LinkedIn, GitHub, your other sites, and ideally a Wikidata or Wikipedia entry if you have one. This is the literal markup answer to the disambiguation problem from the entity post: it collapses your scattered mentions into one confident node the engine can name without hesitating. Be honest in it — only list profiles you actually control or that genuinely refer to you — because an engine cross-checks these, and a sameAs that doesn’t corroborate is worse than none.
Eating our own dog food: how this site is wired
None of the above is theoretical here. RankingHacks runs a single connected @graph on every page, built from one source of truth rather than copy-pasted per post. The Person entity (one author, anchored at /about/) is defined once with a sameAs array pointing at the portfolio and social profiles, and every BlogPosting references it by @id — author and publisher are the same resolved node sitewide. Each page emits its WebPage declared isPartOf the WebSite, plus a BreadcrumbList for its channel path, and posts add the Article piece with real datePublished/dateModified. The whole thing assembles into one @graph envelope so a parser sees a connected entity web, not islands.
That’s also why the audit of this site got cited by Perplexity at a middling tool score: the structured data wasn’t doing anything clever, it was just clean and connected, so the retriever could resolve the entity and trust the passage. The lesson generalizes — the win came from removing ambiguity, not from adding tricks. (The deeper reason connected structure matters is the same one behind Google’s chunk-ranking paradigm: engines reason in extractable units and resolved entities, so structure that maps to that wins.)
Validate, then measure the right thing
Two checks close the loop. Validate the markup mechanically — Google’s Rich Results Test and the schema.org validator will catch a broken @id reference or a malformed type, and a connected graph that doesn’t actually connect is a common, silent failure. Then measure the thing that matters, which is not whether you earned a rich-result snippet. As the EEAT-by-LLM work shows, the ground truth for AI search is whether the engine resolves and names you — so the real test is the same one from the citation playbook: run your target queries through ChatGPT and Perplexity and check whether your entity gets attributed. Schema is plumbing. The citation is the water.
The honest bottom line
Structured data in the AI era is the least glamorous, most reliable lever you have — precisely because it isn’t a trick. Connect your schema into one @id-linked graph, anchor a real Person entity with honest sameAs, mark up only the types that describe something true, validate it, and then judge it by whether the machine can name you. That’s the whole setup. It’s the same through-line as the rest of the AI Search · GEO channel: the bar didn’t get weirder, it got cleaner — and clean, connected, honest structure is the version of “schema hacks” that survives the shift from rank-#1 to get-cited.
This is the implementation companion to the GEO citation playbook and the entity-resolution post. Start with what GEO actually is if you’re new to the channel.
Frequently asked questions
Does structured data help you rank higher in AI search or get cited more by ChatGPT?
No. Structured data does not rank you in an LLM, and there is no schema type or property that makes an engine cite you more. What it actually does is disambiguate your entities and hand a retriever clean, machine-parseable structure to work with. It’s a clarity layer, not a ranking lever — table stakes for being understood, worthless as a trick for being promoted.
What is a connected @graph and why does it matter for schema?
A connected @graph is schema where every entity has a stable @id and entities reference each other by that id instead of being published as disconnected islands. Most sites bolt on schema as separate blocks — an Article here, an Organization there — which forces a parser to guess how they relate. Connecting them by @id removes that guessing, so the engine reads one resolved entity web instead of fragments it has to stitch together. That single structural choice does more for entity resolution than any individual property you could add.
Which schema types are actually worth using for AI search?
A small set, wired together: Person (or Organization) as the anchor everything hangs off, WebSite as the publication, Article/BlogPosting as the content unit, BreadcrumbList for hierarchy, and FAQPage only where real questions are genuinely answered. Each references the others by @id rather than restating them. The boring five, connected properly, beat the exotic forty every time — skip speculative “AI-only” vocab and invented future-proof properties.
What does the sameAs property do?
sameAs declares that your listed accounts, profiles, and pages are all the same entity as you — your social profiles, other sites, and ideally a Wikidata or Wikipedia entry. It collapses your scattered mentions into one confident node the engine can name without hesitating, which is the markup answer to the entity-disambiguation problem. Be honest in it: only list profiles you actually control or that genuinely refer to you, because an engine cross-checks them, and a sameAs that doesn’t corroborate is worse than none.