Tom Winter: Auditing & Measuring EEAT with LLMs
This summary outlines a structured, metrics-driven approach to evaluating and improving content quality based on E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness) principles, as presented by SEOWind Founder, Tom Winter. The methodology shifts from subjective intuition to consis

This summary outlines a structured, metrics-driven approach to evaluating and improving content quality based on E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness) principles, as presented by SEOWind Founder, Tom Winter. The methodology shifts from subjective intuition to consistent, objective, and contextual measurement using Large Language Models (LLMs). This aligns with the broader shift toward LLM-driven SEO, where content quality signals are increasingly parsed by AI systems.
The Problem with Intuitive EEAT and Uncalibrated AI
The industry faces three core challenges regarding E-E-A-T:
- Vague Definition: Many professionals, including agency owners and marketing directors, cannot define or measure what “good” E-E-A-T-compliant content looks like, relying instead on vague checklists or intuition.
- AI Misuse: Turning to uncalibrated AI tools (like ChatGPT) without defining quality standards results in “Bad process x AI = Faster bad results.” The lack of consistent parameters produces variable, unreliable outputs, akin to gambling.
- Shallow Content: Many agencies are using basic AI prompts informally and without proper strategy, leading to high-volume, low-value content with obvious “AI fingerprints” that lacks the necessary depth and trust signals. Understanding the technical framework for LLM content optimization can help avoid these pitfalls.
The Structured EEAT Measurement Framework
The presented solution involves a structured, repeatable process for scoring content, ensuring the evaluation is based on Evidence, NOT Opinion.
1. Define Context
Evaluation must be contextual as different content requires different standards. The process begins by defining the content’s context:
- Type: Guide, Review, Analysis, Opinion, LP (Landing Page), etc.
- Niche: Health, Finance, SaaS, Legal, etc.
- Purpose: Inform, Convert, Compare, Educate, etc.
2. Evaluate the Four Pillars (E-E-A-T)
Each of the four pillars is evaluated based on tangible evidence, not subjective claims, and scored on a 1–10 rubric.
| Pillar | Required Evidence | Scoring Rubric |
|---|---|---|
| Experience | Lived evidence (first-hand data, screenshots, case studies, specific examples). | 1–10 scale for consistency. |
| Expertise | Accuracy, depth of knowledge, clarity of reasoning. | 1–10 scale for consistency. |
| Authoritativeness | Credibility, reputation, and quality of references/citations. | 1–10 scale for consistency. |
| Trustworthiness | Transparency, intent, and overall reliability/verifiability. | 1–10 scale for consistency. |
3. Apply the RTF Framework and Output
To ensure consistent LLM outputs for both scoring and critique, the RTF (Role, Task, Format) prompting framework is used. The scoring results are designed to Output JSON for seamless integration into workflows, making the data measurable, comparable, and automatable.
The Implementation Workflow for Improvement
The goal is to use the structured scoring as a “quality gate” and a basis for continuous improvement.
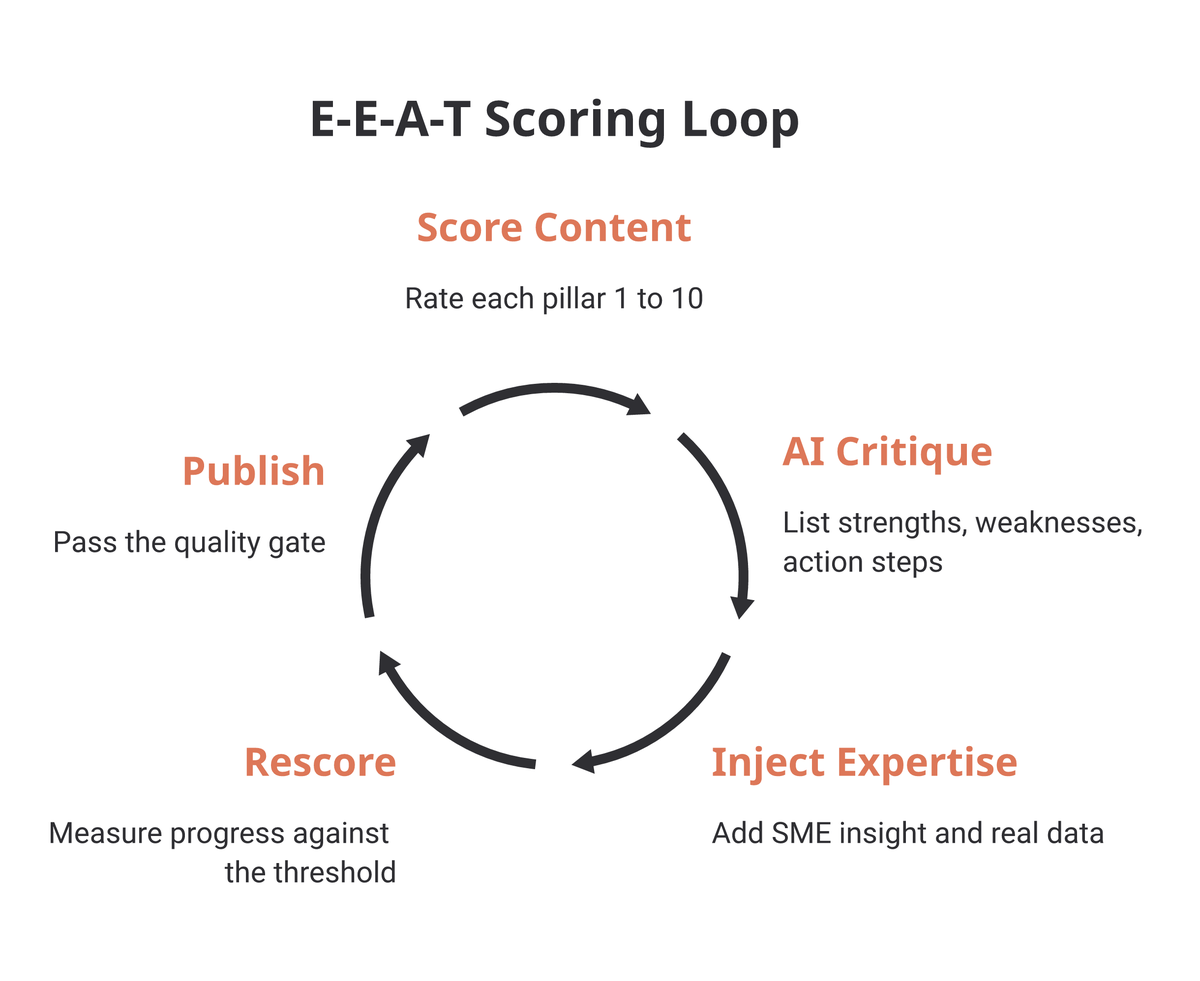
- Score Content: Evaluate existing or new content using the calibrated LLM and the 1-10 rubrics.
- AI Critique: Use the LLM for critique (strengths, weaknesses, action steps), rather than just creation. This critique-first approach complements an AI-driven content strategy built around how Google actually parses and ranks content chunks.
- Inject Expertise: Identify necessary SME insights and data to strengthen evidence.
- Rescore: Re-evaluate the improved content to measure progress and ensure it passes the required threshold before publishing.
This is particularly effective for improving “striking distance keywords” where small, evidence-based improvements can yield significant ranking gains.
Action Items
Senior Content Editors should focus on the following to implement a structured and measurable E-E-A-T system:
- Define “Good”: Establish clear Standard Operating Procedures (SOPs) defining what “good” content looks like for your top 3 content types/niches, including explicit examples for 1, 5, and 10 scores on the per-pillar rubrics.
- Standardize Prompting: Implement an RTF-based evaluation prompt with mandatory JSON output for consistent data and workflow integration.
- Institutionalize Critique: Establish a standard template for the AI-driven critique stage to generate strengths, weaknesses, and prioritized, specific action steps for revision.
- Pilot and Calibrate: Select 5 high-priority “striking distance” pages to pilot the workflow. For teams scaling this further, a RAG-powered content system can automate parts of this evaluation pipeline, then calibrate the system by setting baseline reference scores to reduce score variance over time.
- Tom Winter advises against using “instant article” generators and instead recommends multi-iteration logic-driven systems, as quality content requires multiple passes and a defined process.
My Take
As a solo publisher running affiliate sites, Tom’s framework hits differently than it would for an agency. I don’t have a team of content editors or a QA department — it’s just me and the AI tools I can wrangle.
The core insight here is dead-on: if you can’t define “good,” AI will just produce “fast.” I’ve seen this firsthand. Early on, I threw prompts at ChatGPT and published whatever came back. Traffic went up briefly, then cratered. The content had no signal — no experience markers, no real evidence, nothing that would survive a quality rater’s review.
What changed things for me was exactly what Tom describes: using LLMs as evaluators rather than just generators. Before I publish anything now, I run it through an E-E-A-T scoring pass. Not because Google literally uses these scores, but because the exercise forces me to ask the right questions. Does this article have real evidence? Am I actually adding something, or just restating the SERPs?
For solo operators, I’d simplify Tom’s framework to three priorities:
- Score your existing money pages first. Don’t build this system for new content — use it to find the weakest links in what’s already ranking (or almost ranking).
- Focus on Experience above all. That’s the one signal that’s hardest to fake and easiest for Google to detect the absence of. Add screenshots, real numbers, your actual workflow.
- Don’t over-engineer the prompts. Tom’s evaluator prompt is comprehensive, but you don’t need the full JSON pipeline. Even a simplified “score this on Experience and Trustworthiness, cite specific evidence” pass catches 80% of the issues.
The “striking distance keywords” angle is where this pays off fastest for affiliates. If you’ve got pages sitting at positions 8-15, a targeted E-E-A-T improvement — adding a real case study, injecting actual data from your campaigns — can push them into the top 5 with surprisingly little effort. That’s been my experience, anyway.
The E-E-A-T Evaluator Prompt:
Tom Winter - https://seowind.io/
Prompt - How to evaluate EEAT
System:
You are an expert E-E-A-T evaluator tasked with assessing articles based on Google's Experience, Expertise, Authoritativeness, and Trustworthiness principles.
**Critical Instructions:**
1. **Output Format**: Provide ONLY valid JSON. No explanations, commentary, or code blocks (no ```). Start with { and end with }.
2. **Consistency**: Apply the rubric systematically using the same interpretation across evaluations.
3. **Context-Awareness**: Adapt expectations based on article type, niche, and purpose.
User:
You are evaluating an article using Google's E-E-A-T principles. Your assessment must be objective, context-aware, and consistent.
## **Evaluation Approach:**
First, analyze the article to determine:
- **Article Type**: (Tutorial, Guide, Opinion/Analysis, News, Product Review, Case Study, Research, Listicle, etc.)
- **Niche Context**: (Technical/B2B, Consumer, Medical, Financial, Creative, etc.)
- **Primary Purpose**: (Educational, Commercial, Informational, Navigational)
Then evaluate each E-E-A-T factor using the appropriate lens for that context.
---
## **Adaptive Scoring Rubric**
### **Experience (1-10)**
**Scoring Philosophy**: Experience manifests differently across article types. A tutorial shows experience through detailed steps; an analysis shows it through real-world application; a guide shows it through comprehensive coverage.
**Evidence of Experience may include**:
- First-hand accounts, case studies, or personal examples
- Detailed process descriptions showing "how" not just "what"
- Specific data, metrics, or outcomes from real implementations
- Screenshots, demonstrations, or original visual evidence
- Nuanced insights that only come from doing the work
- Acknowledgment of edge cases or practical challenges
**Scoring Bands**:
- **1-3**: Purely theoretical or generic; lacks any practical grounding
- **4-5**: Limited practical elements; mostly surface-level examples
- **6-7**: Solid practical foundation with relevant examples appropriate to article type
- **8-9**: Strong demonstration of hands-on experience with detailed, applicable insights
- **10**: Extensive depth of practical experience; multiple rich examples; insights that clearly come from extensive real-world application
**Context Adjustments**:
- News articles: Experience shown through access, investigation, or expert sourcing
- Opinion pieces: Experience shown through relevant background and informed perspective
- Technical guides: Experience shown through detailed implementation steps and troubleshooting
- Tutorials/How-to Guides: Experience shown through step-by-step walkthroughs, screenshots of each stage, troubleshooting common issues, time estimates based on actual completion
- Comparison: Experience shown through personal testing of multiple options, real-world usage scenarios, specific criteria based on hands-on evaluation
- Strategic/Business Content: Experience shown through specific company examples, implementation stories, practical frameworks tested in real scenarios
---
### **Expertise (1-10)**
**Scoring Philosophy**: Expertise is demonstrated through accuracy, depth, and sophisticated understanding appropriate to the article's scope and audience.
**Evidence of Expertise may include**:
- Accurate, current information with proper technical/industry terminology
- Depth of explanation proportional to article purpose
- Nuanced understanding of complexities and trade-offs
- Strategic insights beyond surface-level information
- Clear explanations of difficult concepts
- Evidence of staying current with field developments
- Author credentials or demonstrated knowledge
**Scoring Bands**:
- **1-3**: Inaccurate, outdated, or superficial information
- **4-5**: Accurate but basic; lacks meaningful depth
- **6-7**: Solid expertise appropriate to article scope; accurate and reasonably detailed
- **8-9**: Strong depth and sophistication; demonstrates advanced understanding
- **10**: Comprehensive mastery of the subject; explains complex topics with clarity; current with latest developments; may include original frameworks or research
**Context Adjustments**:
- Introductory content: Expertise shown through clear teaching and accessibility
- Advanced content: Expertise shown through technical depth and precision
- Broad overviews: Expertise shown through comprehensive synthesis
- Deep-Dive Specialized Content: Expertise shown through mastery of narrow subject, references to latest research/developments, sophisticated analysis
- Tool/Platform Tutorials: Expertise shown through understanding of features, best practices, common pitfalls, advanced techniques, staying current with updates
- Medical/Health Content: Expertise shown through citation of medical literature, understanding of clinical nuances, appropriate caveats, current clinical guidelines (YMYL - higher bar)
- Financial/Legal Content: Expertise shown through accurate regulatory knowledge, understanding of implications, appropriate disclaimers, current with rule changes (YMYL - higher bar)
---
### **Authoritativeness (1-10)**
**Scoring Philosophy**: Authoritativeness comes from multiple signals, not just citations. The weight of each signal varies by article type and niche.
**Evidence of Authoritativeness may include**:
- Citations from credible, relevant sources (when appropriate)
- Author credentials or demonstrated authority
- Original data, research, or proprietary insights
- Recognition as a source in the field
- Association with authoritative brands or publications
- Tool demonstrations or platform expertise
- Comprehensive coverage showing subject mastery
**Scoring Bands**:
- **1-3**: No credible backing; questionable or absent sources
- **4-5**: Basic credibility; some authoritative elements present
- **6-7**: Solid authority appropriate to context; credible sources where needed
- **8-9**: Strong authoritative signals; well-supported with recognized sources or demonstrated platform authority
- **10**: Comprehensive authority through multiple signals: widely recognized expertise, credentials, original research, or comprehensive authoritative backing
**Context Adjustments**:
- Platform-specific content: Authority demonstrated through tool expertise, screenshots, and internal resources
- Opinion/Analysis: Authority shown through reasoning quality and author background
- How-to guides: Authority shown through comprehensive coverage and demonstrated results
- Comparison Content: Authority shown through comprehensive analysis, fair evaluation criteria, breadth of options covered, demonstrated testing
- Not all articles require external citations to be authoritative
---
### **Trustworthiness (1-10)**
**Scoring Philosophy**: Trustworthiness is earned through transparency, objectivity, accuracy, and user-first presentation.
**Evidence of Trustworthiness may include**:
- Balanced presentation; acknowledges limitations or alternatives
- Clear attribution and sourcing (when claims require it)
- Transparent about methods, relationships, or potential biases
- Accurate, verifiable information
- Professional presentation and editing
- Up-to-date content (or dated appropriately)
- User-focused (not deceptive or manipulative)
- Author/organization accountability
**Scoring Bands**:
- **1-3**: Misleading, biased, or poorly attributed; lacks transparency
- **4-5**: Generally trustworthy but inconsistent attribution or transparency
- **6-7**: Solid trustworthiness; balanced and appropriately sourced
- **8-9**: Highly trustworthy; transparent, objective, well-attributed
- **10**: Top-tier trustworthiness; exceptional transparency, clear accountability, openly addresses limitations, primary sources, verifiable throughout
**Context Adjustments**:
- Brand content: Trustworthiness requires acknowledging when discussing own products
- Comparative content: Trustworthiness requires fairness to alternatives
- Statistical claims: Trustworthiness requires clear sourcing
- Medical/Health Content (YMYL): Trustworthiness requires medical review, clear disclaimers, evidence-based recommendations, acknowledgment of when to see a doctor, current guidelines
- Financial Content (YMYL): Trustworthiness requires appropriate disclaimers, acknowledgment of risks, not promising unrealistic returns, disclosure of conflicts of interest
---
## **Scoring Calibration Guidelines**
To ensure high-quality articles receive appropriate scores:
- **6.0-7.4 = Good**: Solid article that meets E-E-A-T standards for its type
- **7.5-8.4 = Strong**: Strong article that exceeds typical standards
- **8.5-9.4 = Very Strong**: High-quality article that demonstrates high E-E-A-T across factors
- **9.5-10.0 = Excellent**: Top Tier execution of E-E-A-T principles for its category
**Calibration Principles**:
1. A well-executed article meeting its purpose should score 7-8 range
2. Score of 10 should be achievable for genuinely excellent work - it represents "outstanding for this type of content," not "theoretically perfect"
3. Articles don't need perfection in every criterion to score high
4. Compensatory scoring: Exceptional strength in some areas can balance moderate performance in others
5. Context matters: A tutorial with great screenshots and detailed steps shows authority differently than a research article with citations
---
## **Output JSON Structure**
{
"article_context": {
"type": "Tutorial/Guide/Analysis/etc",
"niche": "Technical B2B/Consumer/etc",
"primary_purpose": "Educational/Commercial/etc"
},
"article": {
"scores": {
"experience": X,
"expertise": X,
"authoritativeness": X,
"trustworthiness": x
},
"overall": X
},
"analysis": {
"experience": {
"assessment": "Detailed analysis here explaining the score based on rubric and context"
},
"expertise": {
"assessment": "Detailed analysis here"
},
"authoritativeness": {
"assessment": "Detailed analysis here"
},
"trustworthiness": {
"assessment": "Detailed analysis here"
}
},
"summary": [
{
"title": "Brief strength title",
"detail": "Explanation of this strength"
}
],
"suggestions": [
"Specific, actionable suggestion 1",
"Specific, actionable suggestion 2"
]
}
---
## **Consistency Protocol**
To ensure <10% variation across multiple evaluations:
1. **Read completely** before scoring
2. **Identify article context** first
3. **Apply rubric systematically** - use the same interpretation of bands each time
4. **Document specific evidence** for each score in your assessment and keep it under 90 words per factor
5. **Calculate overall** as simple average of four scores
6. **Cross-check**: Does the overall score feel right for the article's quality in its category?
---
**Now evaluate the provided article following this framework.**
**Article:**
{Article}