Enterprise Content Generation: A RAG-Powered AI System
Introduction and System Foundation The presentation, delivered by Robert Niechciał, focused on an advanced, structured content generation system that drives millions of monthly traffic. The system’s foundation is dify.ai, an open-source, RAG (Retrieval Augmented Generation)-capable AI platform avail
Introduction and System Foundation
The presentation, delivered by Robert Niechciał, focused on an advanced, structured content generation system that drives millions of monthly traffic. The system’s foundation is dify.ai, an open-source, RAG (Retrieval Augmented Generation)-capable AI platform available on GitHub. This platform can be self-hosted on any cloud server to create an enterprise-grade AI solution, providing more control than standard, closed commercial models.
The speaker stressed that single-shot content generation is ineffective because Large Language Models (LLMs) are logical processors rather than knowledge processors, making context and structured knowledge critical for quality output.
The Multi-Step Content Generation Workflow
The core of the system is a structured, multi-step workflow designed to build knowledge before generating content, minimizing the risk of hallucination and topic drift.
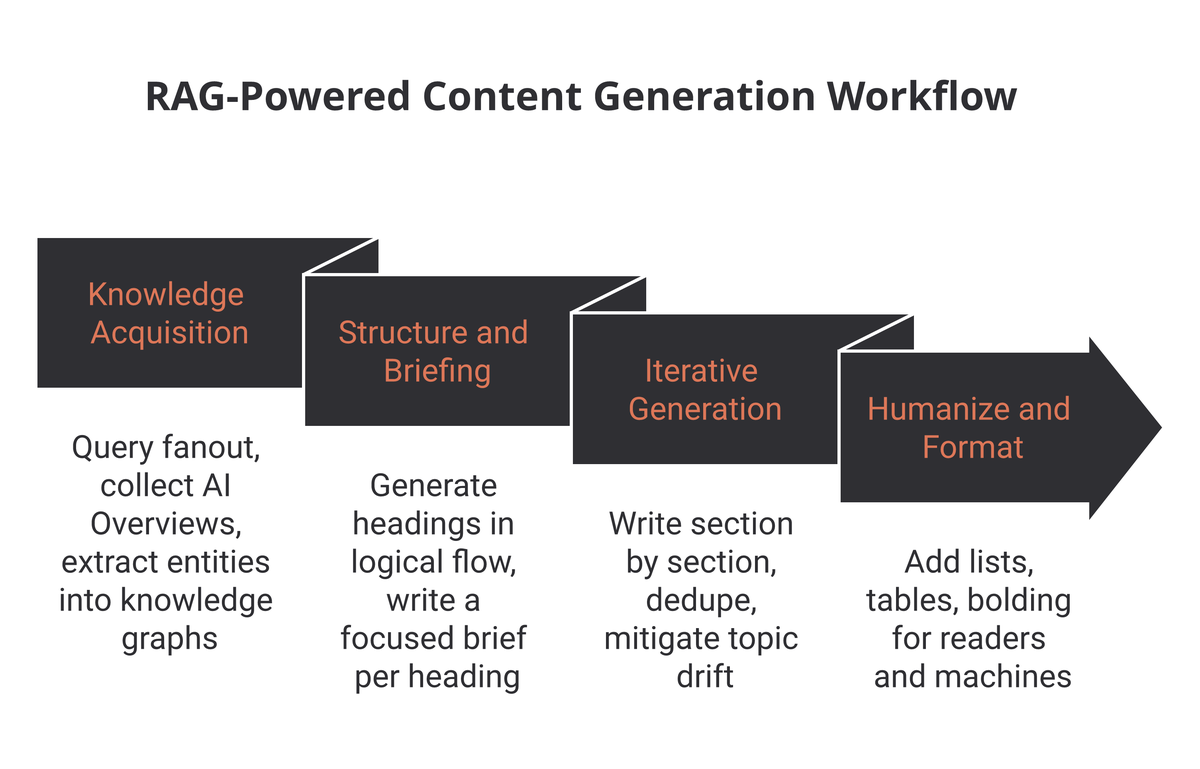
1. Knowledge Acquisition
- Query Fanout: Starting with a target keyword (e.g., “the best beer in Thailand”), the system performs a query fanout, generating 5-6 related questions to cover the topic comprehensively.
- AI Overview Consensus: The system then queries Google for these questions and collects AI Overviews (or high-confidence summary answers). This data is treated as the high-trust knowledge input, alongside content scraped from approximately 50-60 relevant URLs.
- Extraction: The system extracts brands and entities, classifying user intent and building knowledge graphs using the subject-predicate-object format to model relations similar to how search engines understand them.
2. Structure and Briefing
- Heading Generation: Headings are generated based on the collected knowledge, not randomly. A critical principle is logical flow, where each subsequent heading builds upon the information presented in the previous one to create a coherent narrative.
- Content Brief: For each heading, a focused brief is created, specifying the relevant knowledge graph context and the keywords/entities to be included.
3. Iterative Content Generation
Content is generated using a “divide and conquer” approach, section-by-section (heading-by-heading), which significantly reduces the LLM’s long-context hallucination risk.
- Iteration Check: After each section is generated, it undergoes a deduplication check against previously written content to ensure consistency.
- Mitigation: The process includes steps to mitigate common AI issues:
- Perplexity Mitigation: Rewriting to reduce the likelihood of the LLM generating off-topic content.
- Topic Drift Mitigation: Preventing the topic from drifting away from the core subject.
- Readability: Optimizing the text using metrics similar to the Flesch–Kincaid reading ease scale.
4. Humanization and Formatting
The final step focuses on making the content functional for both humans and machines:
- Formatting: The system applies formatting like listicles, tables, and bolding to improve human readability and aid machine processing and retrieval (e.g., for featured snippets).
System Architecture
The core architecture uses:
- Database: SQL database for storing all scraped content, queries, entities, and knowledge graphs (e.g. using Sequel Ace).
- Orchestration: Python for automation and coordinating the multi-step pipeline.
- AI Layer: dify.ai (The RAG-capable LLM platform).
- Interface: A simple, table-like UI for workflow management.
My Take: What This Means for Solo Publishers
I saw Robert Niechciał present this at Chiang Mai SEO 2025, and it was one of the more technically impressive talks — a real production system generating millions of visits, not a proof of concept. But here’s the thing: most of what he showed is not directly replicable by solo publishers. And that’s fine. The value is in understanding the principles, not copying the exact stack.
What’s Actually Useful Here
The “divide and conquer” approach to content generation is the single most transferable idea. If you’re using AI to write anything longer than 500 words, generating it section-by-section with focused context will produce dramatically better output than a single prompt. I’ve been applying this to programmatic SEO content and the quality difference is night and day.
Knowledge-first, writing-second. Robert’s system spends most of its compute on research and knowledge graph construction — the actual writing is the easy part. This mirrors what I’ve found works on PhotoWorkout’s affiliate roundups: the better your research phase, the less editing you do later. The AI Overview consensus trick (using Google’s AI summaries as a high-trust knowledge source) is clever and easy to replicate manually or with a simple script.
The entity extraction and knowledge graph approach maps directly to what Michał Suski found about topical coverage — covering 74%+ of relevant entities is the strongest ranking signal. Robert’s system automates entity discovery; you can approximate it with NLP tools or even by analyzing “People Also Ask” clusters.
What I’m Not Implementing
The full dify.ai stack. Self-hosting an orchestration platform makes sense when you’re generating thousands of posts. For solo publishers doing 5-10 posts per month, the overhead isn’t justified. A well-structured prompt chain in Claude or GPT achieves 80% of the result.
The SQL database layer. Robert stores everything — scraped content, entities, knowledge graphs — in SQL for cross-referencing. Again, enterprise-scale tooling. For smaller operations, a structured JSON or Markdown knowledge base works fine.
Perplexity mitigation as a separate step. If you’re generating section-by-section with good context, topic drift largely solves itself. The separate mitigation pass is an insurance policy for high-volume production where you can’t manually review everything.
The Real Lesson
What Robert is really demonstrating is that the future of content generation is pipeline engineering, not prompt engineering. A single brilliant prompt will never match a structured system that researches, plans, generates, and validates in discrete steps. This is the same insight behind Google’s chunk-ranking paradigm — search engines evaluate content in sections, so generating it in sections makes sense.
For solo publishers, the practical takeaway is: break your AI-assisted writing into phases. Research separately. Outline separately. Write section-by-section. Review against your knowledge base. You don’t need dify.ai to do that — you just need discipline.
If you’re interested in Robert’s broader thinking on AI and SEO, his earlier talk on AI integration strategies provides the foundational philosophy behind this system. And for the technical side of optimizing content for LLM retrieval, the LLM content optimization framework complements this well.
Action Items
The presenter offered to share detailed prompts and scenarios that could be imported into dify.ai to replicate the process.
- Sign up to SensAI Academy to receive the full set of prompts and scenarios for content generation and GraphRAG knowledge extraction.
- Evaluate self-hosting dify.ai to build an enterprise-grade, custom AI content solution.
- Pilot the heading-by-heading generation process within content operations to reduce content drift and hallucination.