Entity SEO: How AI Engines Decide Who to Trust
Answer engines don't trust pages — they trust entities. Before ChatGPT or Perplexity names you, it has to know who you are and decide you're reliable. This is how that resolution works, the four rungs from mentioned to cited, and the signals that move you up them.

The playbook for getting cited lists “resolve as a clean entity” as one of seven moves. This post is the long version of that one line, because it’s the move most solo publishers underrate — and the one that quietly decides whether all the other work pays off. Here’s the uncomfortable mechanic underneath every AI answer: the engine doesn’t trust your page. It trusts an entity — a person, a brand, a thing it can name — and your page only earns a citation once it’s attached to one the model already believes.
That distinction is the whole game. Classic SEO trained us to think in URLs and rankings. Answer engines think in entities and relationships. You can write the best passage on the internet, and if the model can’t work out who wrote it and whether that who is reliable, it will lift your fact, strip your name, and credit nobody — or credit a competitor it recognizes. The win condition moved from rank the page to be the entity.
Retrieval finds the passage. An entity gets the credit.
Both ChatGPT and Perplexity run on passage-level retrieval: the engine pulls the specific block that answers a sub-query and grounds its answer on it. But retrieval and attribution are two different steps. Retrieval asks which text answers this? Attribution asks whose text is this, and do I trust them enough to say their name? You can win the first and lose the second — get retrieved, get paraphrased, and never get named.
Attribution is an entity problem. The model is trying to map a chunk of text back to a node it has a confidence score for. If your identity is ambiguous — three different author bylines, no About page it can anchor to, a name that collides with five other people — the safest move for the engine is to not attribute at all. Ambiguity is treated as risk, and risk doesn’t get cited.
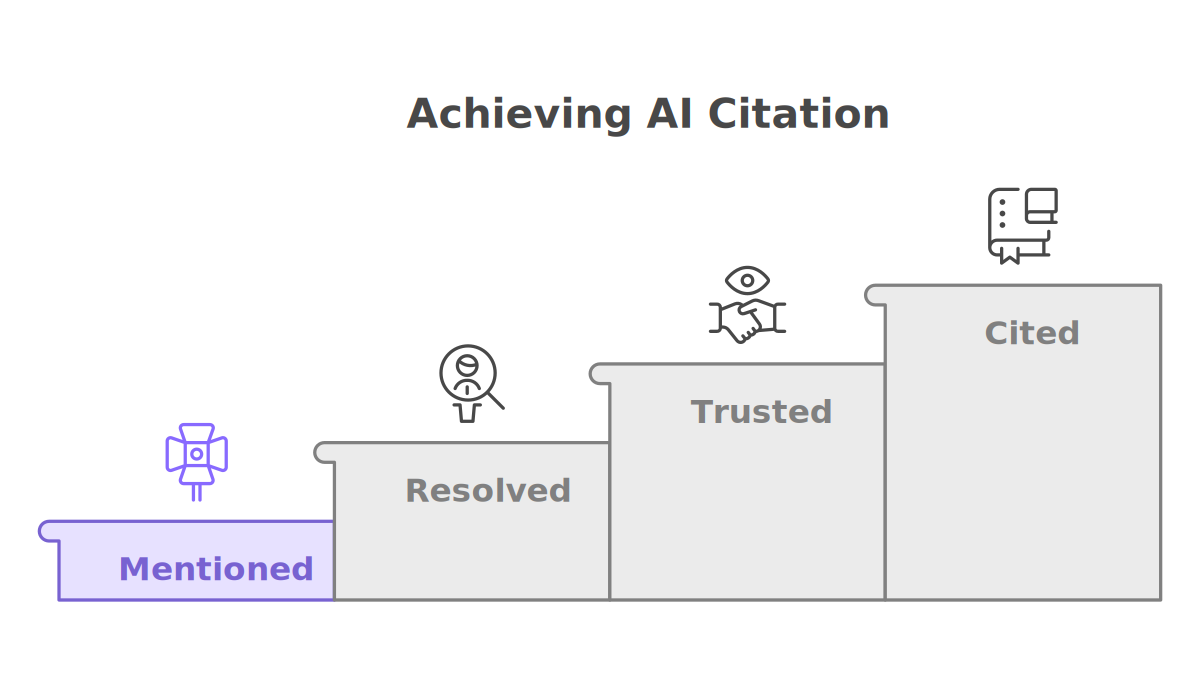
The four rungs
Think of citation as a ladder, not a switch. Most “GEO isn’t working for me” stories are really a source stuck on one specific rung.
- Mentioned — your name appears somewhere the model reads: your own site, a forum, a roundup. This is table stakes and also where borrowed authority lives. A mention buys retrieval surface but nothing more.
- Resolved — the engine can tell exactly who you are and disambiguate you from everyone else with a similar name. This is the rung publishers skip, and it’s the one that converts a mention into a usable identity.
- Trusted — consistent, corroborated signals push your entity from “known” to “reliable enough to put in an answer.” This is where EEAT signals do their real work — not as a ranking score, but as a trust score on an entity.
- Cited — the engine names you next to the claim. The payoff rung, and the only one worth measuring.
Skipping rungs doesn’t work. Pouring effort into great content (a Mentioned-rung asset) while your identity stays ambiguous (a Resolved-rung gap) is the single most common way good publishers stay uncited.
What “resolving as an entity” actually means
Resolution is disambiguation. When the model encounters your name, it’s asking: is this the same Andreas who wrote that other piece, runs that site, and has these profiles — or a different one? Every signal that collapses those into one confident node moves you up. Every inconsistency forks them into competing low-confidence nodes, and low-confidence nodes don’t get named.
This is also why a deep topical map does double duty in the AI era: covering an entity exhaustively isn’t just keyword surface area, it’s the strongest evidence to a retriever that this site is the canonical source for this entity. Topical completeness is entity authority wearing an SEO hat.
The signals that resolve you
None of these are exotic. They’re the unglamorous, standard things — which is exactly the point Google’s own AI guidance keeps making: there’s no magic markup, just clean identity done consistently.

- Consistent author identity. One name, one byline, one bio, everywhere. Inconsistency is the cheapest way to fork yourself into two weak entities.
- A real About page. Not boilerplate — a page substantial enough for the model to anchor a
Person(orOrganization) entity to. This is the canonical home of your identity; ours points back to a single author on purpose. sameAslinks. Tie your identity to the profiles the model already trusts — your LinkedIn, your X, your GitHub, your publisher pages.sameAsis literally the markup that says “these accounts are all the same entity as me.”- Corroborating mentions. Being discussed where the model looks — Reddit, forums, other people’s posts — is third-party evidence your entity is real and matters. You influence whether your name shows up there even though you don’t own the page.
- Topical depth. A site that covers its subject exhaustively reads as an authority on that entity, not a tourist.
- First-hand data. The one signal a competitor can’t copy. Original numbers, a test you ran, a teardown of your own results — proof that you’re a source, not a synthesizer.
Notice what’s not on the list: a special llms.txt cheat file, bought brand mentions, speculative AI-only schema. Those are the parts of “entity SEO” that are easy to sell and don’t survive contact with how the engines actually resolve identity.
Same entity logic, different patience
ChatGPT and Perplexity both run this trust ladder, but they climb it on different clocks. Perplexity is retrieval-first, so a freshly resolved entity with clean signals can get cited within days of you fixing them — and because it shows numbered citations, you can watch the promotion happen. ChatGPT leans on memory, so a chunk of your entity’s reputation is baked into training weights you can’t edit this quarter; resolving cleanly now compounds into citations later, and pays off immediately only on the prompts where it browses. Same destination, different lag. Fix your entity signals for Perplexity’s fast feedback loop; trust that the same work banks slowly with ChatGPT.
The honest bottom line
Entity SEO sounds like a new discipline, but it’s mostly old hygiene with the stakes raised. Consistent authorship, a real About page, honest sameAs links, original data — none of that is novel, and none of it is gameable. What changed is that ambiguity used to cost you a little ranking signal and now costs you the citation outright, because an answer engine would rather name nobody than name the wrong entity. That’s the through-line of the whole AI Search · GEO channel: the bar didn’t get weirder, it got higher, and the publishers who win are the ones the machine can name without hesitating.
This is the entity-resolution companion to the GEO citation playbook. Start with what GEO actually is if you’re new to the channel, then the audit of this site for what these signals looked like in practice.
Frequently asked questions
What is entity SEO and why does it matter for AI engines?
Entity SEO is the work of being recognized as an entity — a person, brand, or thing an engine can name — rather than just optimizing a page. Answer engines like ChatGPT and Perplexity don’t trust your page; they trust an entity, and a page only earns a citation once it’s attached to one the model already believes. The win condition moved from ranking the page to being the entity.
What are the four rungs from mentioned to cited?
The four rungs are Mentioned, Resolved, Trusted, and Cited. Mentioned means your name appears somewhere the model reads; Resolved means the engine can tell exactly who you are and disambiguate you from others with a similar name; Trusted means consistent, corroborated signals make your entity reliable enough to put in an answer; and Cited means the engine names you next to the claim. Skipping rungs doesn’t work — most “GEO isn’t working for me” stories are really a source stuck partway up.
What signals help an AI engine resolve you as a trusted entity?
Six signals do the work: consistent author identity, a real About page, sameAs links, corroborating mentions, topical depth, and first-hand data. None of them are exotic — consistent identity and original data do more than any AI-only markup ever will. Notably not on the list are an llms.txt cheat file, bought brand mentions, or speculative AI-only schema.
Do ChatGPT and Perplexity handle entity trust differently?
They run the same trust ladder but climb it on different clocks. Perplexity is retrieval-first, so a freshly resolved entity with clean signals can get cited within days, and its numbered citations let you watch the promotion happen. ChatGPT leans on memory baked into training weights you can’t edit this quarter, so resolving cleanly now compounds into citations later and pays off immediately only on prompts where it browses.