Alan CladX: Manipulating LLMs and AI Source Poisoning
This summary captures the core insights from the presentation by Alan CladX, a French SEO expert with 26 years of experience, on techniques for influencing and manipulating Large Language Models (LLMs) and their generated content. Key Metrics, Systems, and AI Vulnerabilities The presentation focused

This summary captures the core insights from the presentation by Alan CladX, a French SEO expert with 26 years of experience, on techniques for influencing and manipulating Large Language Models (LLMs) and their generated content.
Key Metrics, Systems, and AI Vulnerabilities
The presentation focused on specific weaknesses in how AI systems ingest and validate information, providing vectors for manipulation:
Structured Data and Language Bias
- JSON Format: CladX described JSON as “the syntactic cocaine of artificial intelligence” because AI systems prioritize structured data and often do not verify the content within it. This allows for manipulating information, such as changing competitor pricing or product reviews.
- Language Effectiveness: English is the most effective language for influencing AI systems because their datasets are primarily English-based. English content requires fewer words to be parsed effectively (around 1,000 words) compared to French (around 3,000 words).
Backlinks and Discovery
- Backlink Role: Backlinks are primarily useful for helping AI systems discover content rather than for authority metrics like domain authority. This aligns with the broader shift toward LLM-driven SEO where traditional ranking signals are being reinterpreted.
- Link Impact: The number of links has no direct impact on the AI’s opinion; they help generate a slug/anchor reference database.
- Design: AI systems do not care about CSS; they read, they don’t look. They do not evaluate design elements, CSS, or fonts, focusing solely on content.
LLM Sitemaps and Crawling
- LLM Sitemaps: CladX stated that LLM sitemap files are ineffective, as based on his tests across 100,000 websites, not a single bot accessed these files.
- Source Democracy: AI outputs reflect the majority and freshness of sources. More, newer sources override fewer or stale ones. Reddit is an example of a historically heavy feeder source for AI training, though its weight has reduced from 40% to 20%.
Actionable Takeaways for LLM Manipulation
Targeted Content Delivery (Cloaking)
- Traditional Cloaking: Traditional SEO cloaking techniques (white text on white background, user agent detection) still work effectively on AI systems.
- Safe AI Folder Strategy: Create a separate folder (e.g.,
/AI/) containing simple HTML pages with targeted content.- Block general search engines via
robots.txt(User-agent: * Disallow: /AI/). - Explicitly Allow AI crawlers (
User-agent: GPTBot Allow: /AI/). This prevents search engine penalties while influencing AI systems.
- Block general search engines via
Scaling Prompt Injection
To encourage users to prompt AI systems with your content at scale:
- Sharing Buttons: Use prompt injection through sharing buttons that automatically ask AI to summarize your content, embedding instructions to highlight specific elements or exclude competitors.
- Passive Prompting: Implement pop-under windows or hidden iframes (1 pixel) containing prompts that visitors unknowingly trigger.
Case Studies in Misinformation
- Fictional Persona: CladX created the fictional person “Faustine Verneuil” (also “Faustin Bernay”) and successfully manipulated AI systems (ChatGPT, Deep AI, Copilot, Perplexity, Grok) to recognize her as a real, famous social media personality.
- Fictional Sport: A fictional sport called “Aquaponey” (“Accompony”) was created and successfully manipulated AI systems and even got major French media outlets to mention it in Olympic Games coverage.
- Cross-Country Manipulation: Information can be transferred by creating content in countries with less AI usage (like Burundi or Chad), validating it through local AI instances, then linking those already-validated sources in target countries.
Defense and Removal Tactics
- Personal Information Removal: Using privacy complaints (involving data like phones, religion, health) can trigger the immediate removal of information about specific individuals from AI systems.
- Monitoring: Monitoring AI responses regularly is crucial for defense (daily for hot topics, weekly for normal, monthly for low-priority). For a structured approach to this kind of monitoring, see how AI chatbot optimization strategies frame the feedback loop between content and LLM outputs.
- Correction: The strategy for correcting misinformation is to identify offending sources and seed 2–3 authoritative, domain-relevant counter-sources to outrank bad narratives.
Alan CladX’s Final Action Items
Alan CladX provided the following actionable guidance:
- Deploy the
/AI/Folder Strategy: Create a folder named/AI/on websites containing simple HTML pages with targeted content and blocking search engines viarobots.txtto influence AI systems without incurring search engine penalties. - Utilize Prompt Injection: Use prompt injection through sharing buttons that automatically ask AI to summarize your content to increase AI exposure.
- Implement Passive Prompting: Suggested implementing hidden iframes or pop-under windows to get visitors to unknowingly prompt AI systems with your content.
- Monitor AI Responses: Advised monitoring AI responses about your brand or topics of interest based on heat (weekly for normal subjects, daily for hot topics).
- Validate Techniques: Recommended testing everything you hear about SEO techniques rather than taking them at face value.
My Take
CladX’s presentation is a masterclass in understanding how fragile AI systems actually are — and that’s both terrifying and useful depending on which side of the manipulation you’re on.
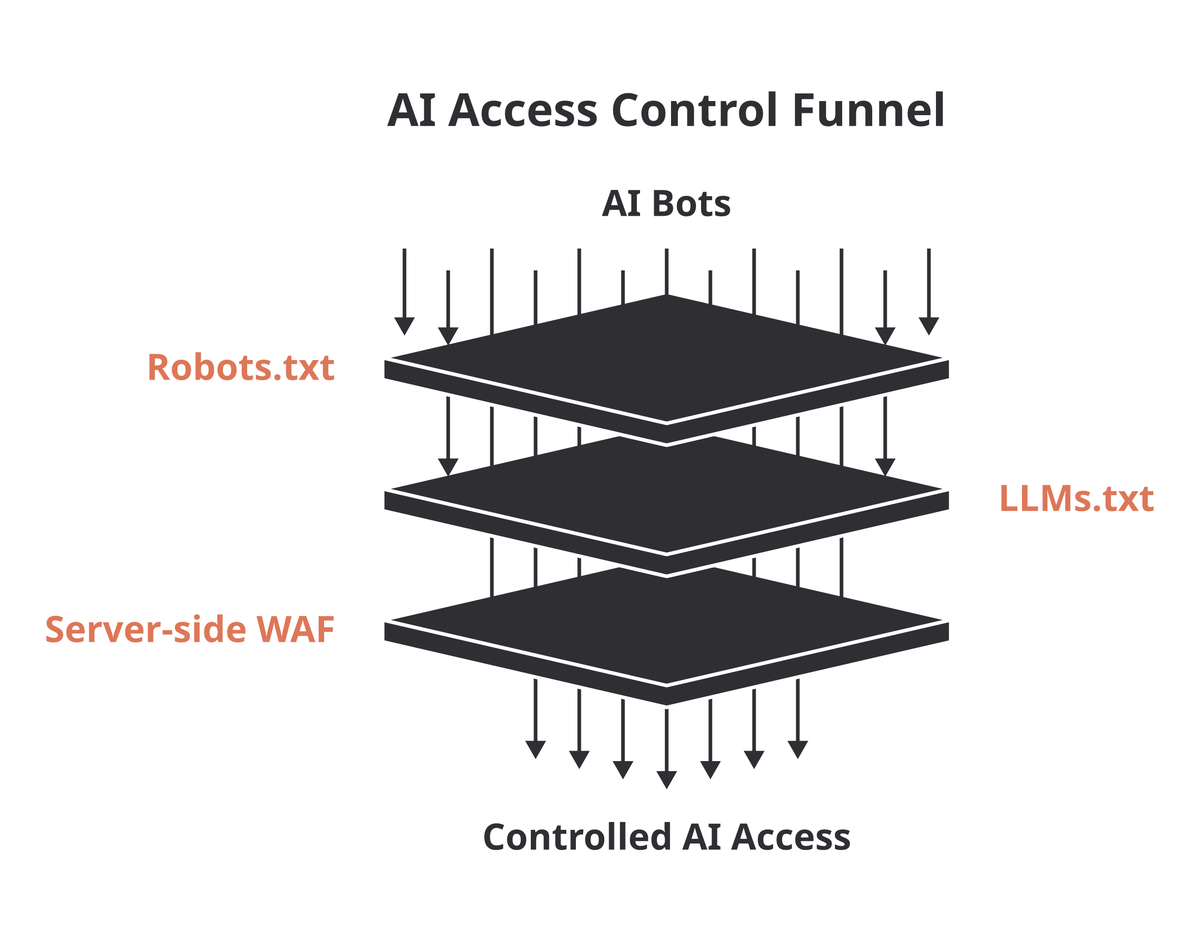
As a solo publisher running affiliate sites, the /AI/ folder strategy is an interesting starting point — low-effort and it addresses a real gap: how do you feed AI crawlers specific content without polluting your Google index? But by Q1 2026, the landscape has shifted significantly. About 13% of AI bots now ignore robots.txt entirely, and the /AI/ folder approach relies on voluntary compliance rather than technical enforcement. The industry is moving toward llms.txt — a root-level markdown file that explicitly guides LLMs to your high-value content, which is proving more effective than directory-based strategies.
The smarter play in 2026 is a layered approach: use robots.txt for general AI crawler management (reputable bots like GPTBot and ClaudeBot still respect it), adopt llms.txt to actively shape what AI sees, and back it all up with server-side controls (WAF rules) to stop unauthorized scrapers that ignore the polite requests. And don’t over-block — restricting all AI bots means you disappear from AI-powered search answers like Google AI Overviews, which are increasingly where traffic comes from.
The JSON-as-structured-data exploit is fascinating but feels like it has an expiration date. AI companies are already tightening their ingestion pipelines, and the window for unverified structured data injection will close. But the underlying insight — that AI systems trust structured formats more than prose — is a durable principle worth building around.
What I find most relevant for publishers is his point about source democracy: AI outputs reflect the majority and freshness of sources. This means consistent, fresh content creation still wins — the same principle behind adapting to AI search. For solo operators who can’t outspend big brands, being faster and more prolific on niche topics is how you shape what LLMs say about your space.
The case studies (Faustine Verneuil, Aquaponey) are entertaining proof-of-concepts, but the real lesson is defensive: if someone can fabricate an entire fictional person and get AI to validate it, imagine what a competitor could do to your brand. The monitoring cadence CladX suggests (daily/weekly/monthly based on topic heat) should be standard practice. If you’re running LLM-optimized content, you need to track what those LLMs are actually saying about you.
The cloaking tactics and hidden iframe suggestions are where CladX ventures into gray/black hat territory. They work — for now. But as someone who relies on long-term organic traffic, I’d be selective about which of these to actually deploy. The /AI/ folder? Yes. Hidden iframes injecting prompts? That feels like a penalty waiting to happen once AI companies catch up.
Bottom line: This talk is essential viewing for anyone trying to understand the offensive and defensive playbook for LLM influence. Take the strategic insights (source freshness, structured data priority, layered AI access control with llms.txt), leave the tricks that won’t age well.